上一期我聊到一个判断:AI 芯片的竞争,正在从单颗芯片里的算力单元,扩展到工艺、封装、互连、验证、EDA 和系统工程。
这一期,我想沿着这个判断继续往下拆一个更具体的问题:既然现在大模型已经能写 Verilog、SystemVerilog,为什么我们还不能说“AI 已经能交付芯片”?
这个问题最近特别值得讲。因为过去两周,几篇和芯片 AI Agent、SVA、EDA 验证相关的新论文密集出现:Phoenix-bench 讨论软件 Agent 能不能迁移到真实硬件工程,Trace2Skill 讨论芯片 AI Agent 如何利用 verifier feedback 进化能力,AssertLLM2 和 SpecAlign 则把注意力放到 SystemVerilog Assertion 的生成、语义对齐和验证评价上。再叠加 Synopsys 在 5 月 28 日 SAFE Forum 2026 上提到的 production-ready AI-powered EDA flow,可以看到一个很清晰的方向:
AI4EDA 的主战场,正在从“能不能生成代码”,转向“能不能接入真实工具链,完成验证、定位、修复和回归”。
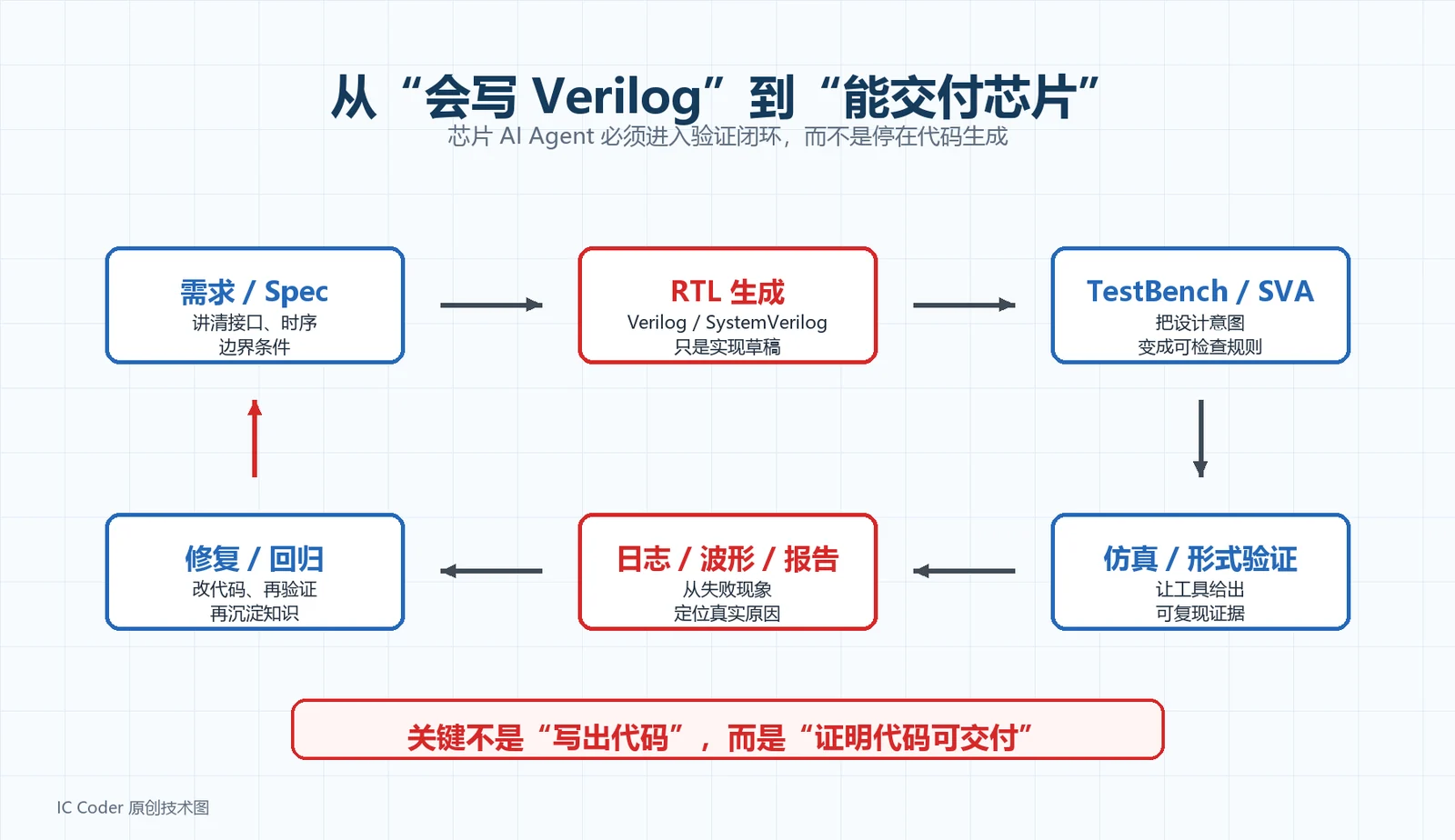
图 1:从“会写 Verilog”到“能交付芯片”,中间隔着需求、TestBench、Assertion、仿真、日志、波形、修复和回归。图源:IC Coder 原创信息图
一、先把话说清楚:Verilog 不是普通软件代码
很多非硬件背景的读者第一次看 Verilog,会把它理解成一种“硬件版编程语言”。这个理解有一半对,也有一半容易误导。
软件代码通常描述的是一串指令怎么执行。比如一个函数先判断条件,再进入循环,再返回结果。调试的时候,我们可以看调用栈、变量值、异常信息,很多 bug 会沿着函数调用链传播。
但 Verilog 描述的不是“程序一步步执行”,而是一堆硬件结构如何在时钟边沿同时变化。一个寄存器什么时候更新,一个 FIFO 什么时候满,一个 valid 信号和 ready 信号在哪个周期同时成立,一个复位信号到底是同步还是异步,这些都不是普通文本逻辑能完全覆盖的。
所以,AI 写出一段 Verilog,只能说明它完成了第一步:生成了一个看起来像硬件设计的草稿。
真正的芯片研发问题,不是“有没有代码”,而是代码能不能在真实约束下被证明是对的。
这里有三个层级,容易被混在一起:
语法正确:代码能不能被编译器或仿真器接受。
行为正确:在关键场景下,信号时序和协议行为是否符合预期。
工程可交付:在足够覆盖的 TestBench、Assertion、仿真、形式验证、综合实现和回归测试下,设计能否稳定通过。
AI 写 Verilog 往往解决的是第一层,最多触碰第二层;但芯片交付真正依赖的是第三层。
这也是我一直不赞同把 AI4EDA 简化成“AI 写 RTL”的原因。RTL 生成是入口,不是终点。验证闭环才是生产力。
二、最近论文的共同信号:评价标准正在从“生成”转向“验证”
5 月 26 日,AssertLLM2 出现在 arXiv 上。这篇论文关注的是 LLM 生成 SystemVerilog Assertions,也就是 SVA。
SVA 可以通俗理解成硬件世界里的“行为契约”。如果 RTL 是“硬件怎么做”,SVA 就是在告诉验证工具:“在某种条件下,这些信号必须满足什么关系。”
例如,一个握手协议里,如果 valid 拉高,那么在某些周期内 ready 应该如何响应;一个 FIFO 如果已经 full,就不能继续写入;一个复位释放后,状态机应该回到合法状态。这些规则写成 assertion 之后,仿真和形式验证工具就可以帮工程师检查设计有没有违背规则。
图 2:AssertLLM2 把 SVA 生成放进 bug-prevention、bug-hunting、formal verification、coverage 和 bug kill ratio 的评价框架中。图源:AssertLLM2,arXiv:2605.27472,2026-05-26
AssertLLM2 的重要性在于,它没有只问“LLM 能不能写 assertion”,而是继续追问:
这个 assertion 语法是否正确?
它能否在 golden RTL 上被证明?
它覆盖到了哪些关键逻辑?
它能不能抓住注入到 buggy RTL 里的真实错误?
它的 bug kill ratio 到底怎么样?
这就比“生成一段看起来像 SVA 的文本”更接近工程真实世界。
硬件验证里最危险的不是 AI 完全不会写,而是它写出一段“看起来对、实际上抓不住 bug”的规则。
同样在 5 月底,SpecAlign 这篇论文也把问题推进了一步。它关注的是 SVA 和自然语言规格之间的语义对齐。
这件事很关键。因为很多时候,AI 生成的 assertion 语法没错,甚至形式验证也能跑,但它不一定真正表达了规格里的设计意图。它可能引入了规格里没有说清楚的假设,也可能把时序条件理解错。
图 3:SpecAlign 通过 property alignment loop 和 SVA alignment loop,检查生成的断言是否与设计规格语义一致。图源:SpecAlign,arXiv:2605.25181,2026-05
这给 AI4EDA 一个很重要的提醒:验证不是只看工具是否跑过,还要看验证目标是否真的对应设计意图。
如果 TestBench 写偏了,AI 会在错误目标上优化;如果 Assertion 语义偏了,AI 可能会给工程师一种“已经验证过”的错觉。芯片研发里,这种错觉非常危险。
三、为什么软件 Agent 不能直接搬到硬件工程里
5 月 13 日,Phoenix-bench 发布。它问了一个很直接的问题:软件工程里的 Agentic AI,能不能迁移到真实硬件工程?
这篇论文的设计很有代表性。它不是让模型在孤立题目里写一个小模块,而是构建了 511 个经过验证的 Verilator 实例,来自 114 个 GitHub 硬件仓库,并配套真实 issue、开发者 patch、fail-to-pass / pass-to-pass testbench 和 Docker 固定的 EDA 环境。
换句话说,它测试的不是“模型会不会写一段题目答案”,而是“Agent 能不能像工程师一样在仓库里定位问题、修改 RTL、跑 EDA 验证、让测试从 fail 变成 pass”。
图 4:Phoenix-bench 要求 Agent 在真实 Verilog/SystemVerilog 仓库中处理 issue,并通过 Docker 化 EDA fail-to-pass / pass-to-pass 测试。图源:Phoenix-bench,arXiv:2605.15226,2026-05-13
结果很有意思,也很冷静。
Phoenix-bench 发现,同一个 Agent 从 SWE-bench Verified 迁移到硬件工程任务时,表现会明显下降。论文里提到,某些 Agent 会从软件任务上的较高表现,掉到硬件任务的 30% 多 resolved rate。更重要的是,硬件任务的失败不是简单“模型不够聪明”,而是任务结构不同。
软件 bug 很多时候沿着函数调用、异常栈、数据结构传播;硬件 bug 则经常沿着信号流、层级实例、时钟、复位、端口位宽、协议时序和 testbench 反馈传播。
所以芯片 AI Agent 不能只做“代码编辑器里的自动补全”。它必须知道:
这个信号从哪个模块来,又流向哪个模块;
这个端口位宽为什么不匹配;
这个状态机为什么在某个周期跳错;
这个 testbench 为什么失败;
这个波形里哪一个周期开始偏离预期;
这个修复是否破坏了其他原本通过的测试。
对芯片 AI Agent 来说,知道“改哪个文件”远远不够;它必须知道 bug 在哪个信号、哪个周期、哪个层级、哪个验证目标上暴露出来。
Phoenix-bench 里最值得关注的一个结果,是 testbench feedback 的作用。
图 5:Phoenix-bench 中,一轮 testbench feedback 对三个交互式 Agent 的 resolved rate 都带来显著提升。图源:Phoenix-bench,arXiv:2605.15226,2026-05-13
论文显示,只告诉 Agent 文件级定位帮助很有限;但给它一轮 testbench log feedback,resolved rate 会有大幅提升。这个结果非常符合工程直觉。
因为在硬件工程里,log 不是附属信息,waveform 也不是“排版好看的调试图”。它们就是工程师判断设计对错的证据链。
没有日志和波形,AI 就像蒙着眼睛改 RTL。
四、Trace2Skill 给出的方向:让 AI 从失败轨迹里学习
如果说 Phoenix-bench 告诉我们“芯片 AI Agent 难在哪里”,那么 5 月 20 日提交的 Trace2Skill 则给出了一个有意思的方向:让 Agent 从执行轨迹和验证反馈里进化自己的技能。
Trace2Skill 面向的是 Complex Verilog Design Problems。论文指出,复杂 Verilog 问题之所以难,是因为 Agent 需要在大仓库里定位和 verifier 相关的 RTL、testbench、include path、build dependency,然后做精确修改,还要从稀疏的 hidden verifier 失败中恢复。
这句话翻译成工程语言就是:真正难的不是写一段模块,而是在一个真实工程里找到“为什么没过”,并把它修到能过。
图 6:Trace2Skill 用 rollout、metrics、oracle lessons、mutation 和 runtime feedback 形成技能演化闭环。图源:Trace2Skill,arXiv:2605.21810,2026-05-20
Trace2Skill 的思路不是简单多采样,也不是重新训练一个 RTL 专用模型,而是把 Agent 的“技能描述”当成可以演化的策略。它会从一次次 rollout 里挖掘成功模式和失败模式,转成更密集的诊断和 lesson,再通过 oracle、mutator、selector 形成下一轮技能。
更通俗地说,它像一个工程师 debug 后写下来的经验卡片:
哪些路径应该先看;
哪些 testbench 失败最关键;
哪些 include 或 build dependency 容易漏;
哪些修复看起来通过局部仿真,但会被 hidden verifier 打回来;
哪些失败模式下,不应该继续沿着错误方向改。
论文在 8 个 hard tasks 上做了对比。seed CVDP agent 原本是 0 通过;加入 dense verifier feedback 和 Trace2Skill 后,最强配置解决了 6/8 个 hard tasks,pass rate 达到 33.6%。
这个数字不是在说“问题已经解决了”,而是在说明一个方向:芯片 AI Agent 的能力提升,不只来自更大的模型,也来自更好的验证反馈、更好的轨迹记录、更好的工程知识沉淀。
五、产业界也在往 production-ready flow 走
这条研究线并不是孤立的。5 月 28 日,Synopsys 在 SAFE Forum 2026 上发布与 Samsung Foundry 的最新合作进展,里面提到 production-ready AI-powered digital and analog flows、DTCO、signoff、AI-assisted ATPG、3DIC Compiler 和 silicon-based test。
我关注的不是新闻稿里的“AI”两个字,而是它和哪些词放在一起:production-ready、PPA、signoff、DFT、ATPG、multi-die、silicon feedback。
这些词背后的意思很清楚:产业界真正关心的是 AI 能不能进入生产流程,而不是只做一个漂亮 demo。
AI4EDA 的真正门槛,不是让模型写出一段像样的代码,而是让 AI 进入可验证、可回归、可追溯、可交付的工程流程。
这也是为什么我认为 AI4EDA 接下来会从“生成式工具”变成“工程智能体”。一个合格的芯片 AI Agent,至少要接住五个接口:
这五个接口连起来,才是我理解的“AI4EDA 工程闭环”。
六、对企业和高校团队的实际启发
如果你是企业里的 FPGA 或数字 IC 团队,我建议不要只问供应商:“你们的模型能不能写 Verilog?”
更应该问:
它能不能接入我的仿真环境?
能不能读懂已有项目结构和模块层级?
能不能根据 testbench 失败日志定位问题?
能不能看 VCD 波形,解释某个信号为什么偏离预期?
能不能生成 assertion,并说明这个 assertion 对应规格里的哪条意图?
能不能在修复后自动回归,确认没有破坏原本通过的测试?
能不能私有化部署,保护代码、规格和项目知识?
如果你是高校、科研院所或课程团队,我也建议把 AI4EDA 教学从“让学生用 AI 写模块”升级到“让学生理解验证闭环”。
因为未来真正有价值的硬件工程师,不是只会让 AI 写代码的人,而是能判断 AI 生成结果是否可靠、能设计验证目标、能读懂波形和报告、能把工程问题闭环的人。
AI 会降低写代码的门槛,但会提高工程判断的价值。
七、我的判断:第二阶段的 AI4EDA,拼的是闭环能力
把最近这些论文和产业动态放在一起,我的判断很明确:
AI 写 Verilog 会越来越容易,但 AI 交付芯片不会因为“会写”就自动发生。真正决定 AI4EDA 价值的,是验证闭环能力。
这一轮 AI4EDA 的演进,大概会经历三个阶段:
代码生成阶段:AI 能写 RTL、脚本、TestBench 片段,提升单点效率。
工具链协同阶段:AI 能调用仿真器、综合工具、形式验证、日志分析和回归流程。
工程闭环阶段:AI 能基于证据定位问题、提出修复、重新验证,并把经验沉淀成团队知识。
第一阶段解决“写得快”,第二阶段解决“跑得起来”,第三阶段才开始解决“交付得稳”。
这也是 IC Coder 持续关注 FPGA 和数字 IC 前端研发闭环的原因。需求拆解、Spec、RTL、TestBench、Assertion、仿真、波形、日志、debug、修复、回归和知识沉淀,这些听起来没有“AI 一键造芯片”那么刺激,但它们才是真实工程里每天都要面对的问题。
最后,用一句话总结这一期:
AI4EDA 的核心不是让 AI 替工程师“写完芯片”,而是让 AI 和工程师一起,把设计、验证、调试和回归连成可交付的闭环。
下一期,我想继续沿着这条线,把 TestBench、Assertion 和波形分析单独拆开讲一讲:为什么它们会成为芯片 AI Agent 的验证证据链。
后续也会继续更新 AI4FPGA、Physical AI 与 FPGA、国产工具链适配、企业私有化部署、EDA 报告理解和芯片研发智能体落地案例。关注这个公众号,我们一起把 AI4EDA 从概念聊到工程落地。
参考来源
Trace2Skill,2026-05-20,arXiv:2605.21810,Trace2Skill: Verifier-Guided Skill Evolution for Long-Context EDA Agents:https://arxiv.org/abs/2605.21810
Phoenix-bench,2026-05-13,arXiv:2605.15226,Is Agentic AI Ready for Real-World Hardware Engineering? A Deep Dive with Phoenix-bench:https://arxiv.org/abs/2605.15226
AssertLLM2,2026-05-26,arXiv:2605.27472,AssertLLM2: A Comprehensive LLM Benchmark for Assertion Generation from Design Specifications:https://arxiv.org/abs/2605.27472
SpecAlign,2026-05,arXiv:2605.25181,SpecAlign: A Semantic Alignment Framework for SystemVerilog Assertion Generation:https://arxiv.org/abs/2605.25181
Synopsys,2026-05-28,Synopsys Advances Power and Performance for AI and Multi-Die Designs on Latest Samsung Foundry Processes at SAFE Forum 2026:https://news.synopsys.com/2026-05-28-Synopsys-Advances-Power-and-Performance-for-AI-and-Multi-Die-Designs-on-Latest-Samsung-Foundry-Processes-at-SAFE-Forum-2026